This chapter describes the Omnis XML object (oXML), an external component which allows you to parse and manipulate XML documents in Omnis using the standard Document Object Model (DOM) API. This chapter does not provide an exhaustive description of XML or the DOM, since this can be gained from many other sources.
For further information about XML, you can look up XML-related web sites, and read one or two of the many books available on the subject. Here are one or two resources we found very useful:
XML and DOM standards
www.w3.org has the official XML standards and a lot of good general information; also includes a full definition of the DOM API. A look at the DOM Level 2 definition is very useful, whereas studying the XML specification is not necessary.
Information and Tutorials
www.xml.com has background information on XML and news;
www.w3schools.com/xml has some useful XML tutorials & information.
Omnis Tech Note: you may also like to read the Omnis Technical Note TNXM0001: Creating XML documents with oXML which includes an example library to download.
The interface to XML documents is implemented in Omnis Studio using the standard Document Object Model (DOM) API as an external component which must be instantiated via an Omnis Object Variable. The oXML component addresses the most basic XML requirement, namely the ability to parse and extract information from an XML document, and to generate new XML documents. The oXML component allows you to parse and manipulate XML documents using a standard set of methods provided by the DOM level 2 API, plus some additional methods that speed up the process of building a document. The oXML component also allows you to display an XML document in the tree list component, which is well suited to displaying the hierarchical structure contained in XML documents.
oXML is available as a built-in component in most editions of Omnis Studio and is therefore installed and ready to use. In previous versions of Omnis Studio (pre Studio 6) the oXML component was available as a separate plug-in which had to be purchased and installed separately.
To use oXML to access your XML documents, you need a working knowledge of XML and the DOM. This section provides a short introduction to XML and the DOM. If you are already familiar with these technologies, and/or you have read one of the many sources of information about XML and DOM, then you may like to skip this section.
XML (eXtensible Markup Language) allows you to store, exchange and display data or information in a structured and efficient way. In this respect it is no different from most existing data formats, except that XML provides a higher degree of standardization and flexibility than many other proprietary technologies, opening up many new and exciting opportunities in business computing and information technology. XML has already revolutionized content management, information publishing, and news syndication, as well as other B2B markets, while the adoption of XML across many other industry sectors seems to be gathering pace.
XML allows you to store structured documents or data as text and provides you with a way of manipulating, transforming, and presenting your data in many different formats. For example, information or data stored in an XML document can be displayed in a web browser using a Cascading Style Sheet (CSS). In addition, when XML documents are stored in a database they can be queried and retrieved much like any other data source.
The business benefits of using XML and XML-based systems are well documented in the IT industry and media. XML, or rather technologies that use XML as their basis, promise to provide the IT industry with greater standardization, interoperability, efficiency, and present the potential for many new technologies. If you are an application developer, you will no doubt be asked some time in the future to create applications that will “handle XML”.
Platform Independent and Reusable
XML is machine and platform independent so it can be exchanged between one system or network and another. Plus, once information is in XML format it can be reused for many different purposes for digital and printed publication.
Worldwide Standard
XML is a standard language defined and ratified by the W3C consortium so it is not controlled or owned by any one company. This ensures the future of XML as an open standard employed by the whole IT industry.
Information exchange
Since XML is an agreed standard it affords a high degree of information exchange, in particular between networks, businesses and other interdependent organizations.
New Business opportunities
The standardization and flexibility of XML mean that many existing business problems can be solved more efficiently, while many new business opportunities will arise that take advantage of XML. For example, XML has already revolutionized Content management, publishing & news syndication, and will transform many other areas of business, particularly those suited to automation.
XML is very much like HTML, but it differs in one or two important ways. Like HTML, XML uses tags to define the "elements" (content or data holders) within a document, but unlike HTML, XML tags only describe the data or content, they do not contain any information about the display or formatting of the content or document as a whole. Each element must have a start and an end tag, and tag names are case-sensitive.
HTML conforms to a standard set of tags, whereas XML element names can be anything you like providing a better description of each piece of data or the content in your document. For example, to create a file to store the contents of a bookstore you can create an element called <bookstore> to contain the information about all the books. XML documents are often described as having “meta-data” since the information in the tags describes the data within the tag itself. In this case, someone looking at the file containing the tag <bookstore> can see immediately that the information relates to a bookstore.
Elements within a document are often nested in a hierarchical structure, building a more detailed or structured picture of the thing or things being described in the document. Therefore, individual elements are referred to as “nodes”. The top level element in a document is called the "root node", which has an ID of 0, and all elements inside it are called "child nodes" which have unique IDs identifying them. Carrying on the book example, the <bookstore> element or root node could contain elements for <book>, <title>, <author>, <publisher>, and <isbn>, plus you can further describe the <author> element using <firstname> and <lastname> child nodes. An XML document with these elements or nodes would have the following structure:
<?xml version="1.0"?>
<bookstore>
<book>
<title>Essential XML for Web Professionals</title>
<author>
<firstname>Dan</firstname>
<lastname>Livingstone</lastname>
</author>
<publisher>Prentice Hall PTR</publisher>
<isbn>0130662542</isbn>
<price>34.99</price>
</book>
<book>
<title>Professional XML (Programmer to Programmer)</title>
<author>
<firstname>Mark</firstname>
<lastname>Birbeck</lastname>
</author>
<publisher>Wrox Press, Inc</publisher>
<isbn>1861005059</isbn>
<price>59.99</price>
</book>
</bookstore>Note the <firstname> and <lastname> elements are nested inside the <author> element, while all sub-nodes are contained in the <bookstore> root node. Also note the obligatory XML declaration at the beginning of the document which defines the XML version of the document; this is a processing instruction that gets sent to the XML parser.
Like HTML, elements can have "attributes" (properties) that further describe the element, but again they do not provide any information about the display of the data. For example, the <book> element in our sample xml above could have the attribute “genre” which is written like this:
<book genre=”Computing”>Note that genre is a general characteristic of a book and is therefore considered an attribute of a book (i.e. many books may be in the same genre), whereas the title of a book is unique to each book and is therefore described in an element as part of an individual book.
Entities let you represent a single character, a number of characters, or a string of words using a short alias name. There is a range of ISO approved entities that have reserved name and number codes to represent specific characters, such as & for ampersand, < for lesser than, > for greater than, " for double quotation mark, ' for apostrophe, and € for the Euro symbol, and so on. You can also define your own custom entities in your XML documents in the document template, either internally quoted in the DTD (Document Type Definition: see below) or they can be listed in an external file. For example, you could represent a publisher name by declaring <!ENTITY ph "Prentice Hall PTR">, therefore writing the publisher name as &ph; in the body of your document.
Entities that hold text, like those described above, are called parsed entities. You can also create entities for non-text data or files, such as image files, video, binary files, or even other applications, and these are called unparsed entities, but they are also referred to as notations.
When a document has all the correct start and end tags and is properly nested, it is described as "well-formed". XML documents are processed through an XML parser which checks for correct syntax or “well-formedness”. Documents can be further validated against a template or Document Type Definition (DTD), or a schema. A DTD is itself a text document which contains a description of the elements and entities for a particular type of XML document, in other words, it specifies what type of data or content the document can contain. The DTD would contain a list of elements allowed in the XML document, defining the name and data type for each element. The DTD for an XML document can be included inline, as part of the XML document itself, or it can be a separate file referenced in the XML document.
<!DOCTYPE BOOKS [
<!ENTITY PH "Prentice Hall PTR">
<!ELEMENT book (TITLE,AUTHOR,PUBLISHER,ISBN)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (FIRSTNAME,LASTNAME)>
<!ELEMENT firstname (#PCDATA)>
<!ELEMENT lastname (#PCDATA)>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT isbn (#PCDATA)>
]>Most of the time you will need to use an industry standard DTD, rather than creating your own. Using standard DTDs ensures the portability of your data or documents across many different applications and between organizations.
Increasingly, DTDs are being superceded by schemas, or w3c schemas as they are sometimes called. oXML supports the use of schemas to validate XML documents. Like DTDs, schemas define the structure and types of data allowed in documents but they provide greater control over the structure and types of data in your XML documents. Schemas use XML namespaces to define the elements and attributes in your XML documents. Namespaces are unique names that identify element types and attribute names.
Schemas are themselves written in XML so you can create and manipulate them using oXML. Schemas are more powerful than DTDs since you can define the type and constraints on the data in your documents. Schemas can contain a number of built-in data types, such as, xs:string, xs:decimal, xs:date, xs:anyURI, and you can create your own custom types. Like DTDs, schemas can be referenced externally in your XML documents: see below.
The differences between DTDs and Schemas become apparent when you compare one with the other, for example, the following DTD called note.dtd describes the structure of a very simple XML document.
<!ELEMENT note (to, from, heading, body)>
<!ELEMENT to (#PCDATA)>
<!ELEMENT from (#PCDATA)>
<!ELEMENT heading (#PCDATA)>
<!ELEMENT body (#PCDATA)>The DTD defines the ‘note’ root node as having four child nodes (to, from, heading, body). The DTD is placed in the XML document itself or referenced externally.
A simple schema called note.xsd can be used to define the same structure:
<?xml version="1.0"?>
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="note">
<xs:complexType>
<xs:sequence>
<xs:element name="to" type="xs:string"/>
<xs:element name="from" type="xs:string"/>
<xs:element name="heading" type="xs:string"/>
<xs:element name="body" type="xs:string"/>
</xs:sequence>
</xs:complexType>
</xs:element>
</xs:schema>The schema defines the ‘note’ complex element that contains four simple elements (to, from, heading, body).
The XML DOM Document object has some properties to allow you to specify and use an external schema file (XSD) for validation.
You should set $fullschemavalidation to true unless performance is an issue.
The other new properties allow an external schema to be specified:
$nonamespaceschemalocation
if specified, this property becomes the noNamespaceSchemaLocation attribute for the document being parsed.
$schemalocation
if specified, this property becomes the schemaLocation attribute for the document being parsed.
The schemas specified in these properties need to be referenced by a pathname to the schema file.
For example, to use an external schema, turn on $fullvalidation (without this, the absence of the schema file is an unreported and ignored warning), and set $schemalocation to:
"urn:books c:\dev\studio60orfc\oxml\test\books.xsd"where the second component is the path to the schema file on your system.
If an XSD is in the same directory as the XML, you can use:
"urn:books books.xsd"An XML parser or processor is a software module that checks your documents for “well-formedness” and performs validation against a DTD. The XML parser provided with oXML, called Xerces (called ‘xerces-c_3_1.dll’ under Windows), is a validating parser that allows you to read and write documents as well as perform validation against a DTD or schema. The Xerces parser is in the root of the Omnis Studio folder, in the same location as the Omnis.exe program. Under macOS, the parser library is called Xerces.Classic.Lib and it is bound into the oXML component.
Most recent browsers will display XML documents in a collapsible/expandable format. For most purposes though, you need to extract data from your XML documents for subsequent data processing, or enumerate an entire document in order to build a list for display in an Omnis tree list.
The display or transformation of the XML data is handled at the time of delivery when the document is retrieved from a document store and displayed on a client machine. The idea of XML is to store your data in a raw but structured state, allowing you to query and present it in many different ways as and when required.
To use oXML to access your XML documents, you need some knowledge of the DOM. Like XML, the DOM API is well documented in print and on the web so consult these external sources for further information.
The Document Object Model (DOM) is an API that allows you to build documents, navigate their structure, and add, modify, or delete elements and content. To quote from www.w3c.org, the “Document Object Model (DOM) is an application programming interface (API) for XML [and HTML] documents. It defines the logical structure of documents and the way a document is accessed and manipulated. In the DOM specification, the term “document” is used in the broad sense - increasingly, XML is being used as a way of representing many different kinds of information that may be stored in diverse systems, and much of this would traditionally be seen as data rather than as documents. Nevertheless, XML presents this data as documents, and the DOM may be used to manage this data.”
The oXML component uses the DOM Level 2 API to access XML documents, as defined on the W3C web site. It is built upon source code provided by the Xerces project, available as part of the Apache XML project: please see their web site for background information (http://xml.apache.org). For our purposes, the DOM provides a platform-independent interface to XML documents so that Omnis developers can use Omnis code and the notation to navigate and manipulate XML documents. DOM treats an XML document as a hierarchy of nodes, arranged in a tree structure, and accessible via its API and its methods.
The methods available in oXML closely match those defined by the DOM, so for a fuller explanation of the DOM API and its interfaces and methods you should consult the www.w3.org web site, or a good XML book or reference guide. The following URL has a definition of the DOM Level 2 API:
http://www.w3.org/TR/2000/REC-DOM-Level-2-Core-20001113/core.html
The DOM represents a document as a tree of nodes or objects. Each node represents a different part of the document, hence a node can be one of a number of different types of node. In addition, each node or object type can have children, but only certain types of children are allowed for each type of node. The following table shows you what objects are returned (if any) when you query the children of a node in the document tree.
| Node type | Possible Children |
|---|---|
| Document | Element (maximum of one), ProcessingInstruction, Comment, DocumentType |
| DocumentFragment | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| DocumentType | no children |
| EntityReference | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Element | Element, Text, Comment, ProcessingInstruction, CDATASection, EntityReference |
| Attr | Text, EntityReference |
| ProcessingInstruction | no children |
| Comment | no children |
| Text | no children |
| CDATASection | no children |
| Entity | Element, ProcessingInstruction, Comment, Text, CDATASection, EntityReference |
| Notation | no children |
See the Reference section later in this manual for a complete list of properties and methods for each type of node object.
The oXML component is an external object which is a type of external component that contain methods that you can use by instantiating an Object Variable based on the oXML external object. The oXML component is stored in a component library, called Oxml.dll under Windows, and is in the XCOMP folder under the main Omnis folder. The oXML component is always loaded by default so there is no need to load it via the External Components option in the Component Store.
You can add a new XML object in the method editor by inserting a variable of type Object and using the subtype column to select the XML Document object. You can click on the subtype droplist and select the XML object from the Select Object dialog. You can ignore the group of DOM Types: you must create a document object to access the whole of an XML document and use the object’s methods to return the different parts or elements in the document.
An object icon plus the type “DOM Document” will appear in the variable subtype cell showing the type of object.
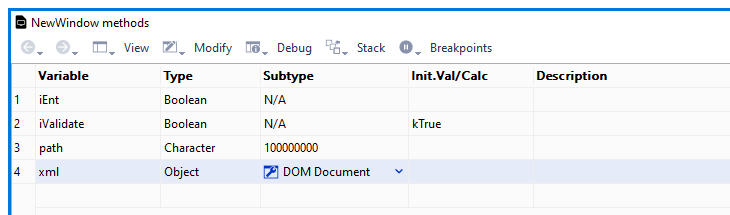
When an instance of the external object has been constructed (in an open window or form), you can inspect its properties and methods during development using the Interface Manager.
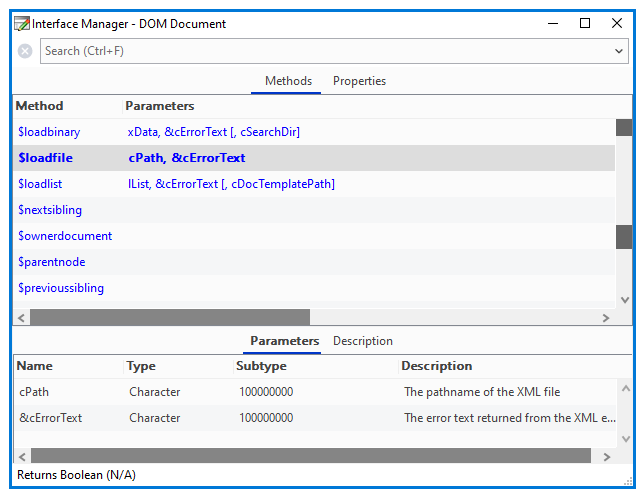
You can drag a method of the XML object from the Interface Manager into the Code Editor for the Do command. For example, when you inspect a DOM Document object (as shown), the Interface Manager will list the methods of a document object as well as the general properties of a node, since the root node is at the head of the document. To load a specified XML document you can use the $loadfile() or $loadbinary method (see below in the section Loading an XML document for the code). While debugging your code, you can inspect an object variable by right-clicking on the variable and selecting the Variable [varname] option. The following shows an object variable containing a document.
If true, the $useobjectrefs property ensures oXML returns object references rather than objects, that is, object return values are object references and object parameters must be object references. This property is automatically set in new returned objects to the value of $useobjectrefs in the object returning the new object.
In the DOM, documents have a logical structure which is like a tree, that is, all the elements and objects in the document are arranged in a hierarchical structure. Each object in a document is treated as a “node”. The objects or nodes in a document can be one of a number of different types: an element, a comment, an attribute, text, or an entity. The oXML component contains a number of different objects, to support the different objects defined by the DOM.
The key object in oXML is the “DOM Document” object, which represents an XML document. You can use DOM Document as the subtype of an object variable, in order to use oXML and access its methods to manipulate your documents.
Having returned an XML document into your object variable, you can use various methods to return the objects within the document. For example, the $documentelement() method returns a DOM Element object that, in this particular case, represents the root of the XML document (see below the section Getting the document root element for the code). You can return and manipulate the following objects:
DOM Attribute
an attribute or property of an element
DOM CDATASection
the CDATA section of an attribute definition
DOM Comment
provides access to the content of a comment
DOM DocumentFragment
allows you to load part of a document into memory rather than the whole document
DOM DocumentType
a list of document types within a document
DOM Element
an element within a document; provides access to an element’s attributes
DOM Entity
an entity within a DTD
DOM EntityReference
the representation of an entity
DOM NamedNodeMap
a collection of unordered nodes within a document
DOM NodeList
an ordered list of nodes within a document
DOM Notation
an unparsed or non-textual entity within a DTD, or the formal declaration of Processing Instruction target
DOM ProcessingInstruction
a special element or tag that provides instructions parsed to an external application, e.g. the XML version declaration at the beginning of a document
DOM Text
the text or content of an element or attribute
These objects are never used directly as the subtype of an object variable. Instead, they are returned by methods of the oXML object.
Having created and instantiated an object variable, based on oXML, you can use its methods to load an XML document, enumerate the different parts or elements of the document, and display it in an Omnis tree list component. The following sections show how you can do this using Omnis methods.
You can use the $loadfile() or $loadbinary() method to load an XML document into the document object (variable).
$loadfile(cPath,&cErrorText)
loads the XML file with pathname cPath into the document object, and returns true for success, or false and cErrorText for failure.
$loadbinary(xData,&cErrorText[,cSearchDir])
loads a document stored in the binary variable xData into the document object; returns true for success, or false and cErrorText for failure; when parsing from memory, cSearchDir is the directory in which the parser looks for externally referenced files.
When the $loadfile() method is executed the specified document is loaded into the object object/variable. In effect, this method loads the whole document, that is, a DOM Document representing the document. The document object has the general properties of a node ($nodename=#Document and $nodetype=kXMLNodeDocument) together with the properties of a document object $parservalidates, $replaceentityreferences, and $outputencoding, as well as many other methods for manipulating or traversing the document tree.
The following method can be placed behind a button and be used to prompt the user to select an XML document. The method then calls a class method to build the tree corresponding to the structure of the document selected by the user.
# Method '$event' for Load XML button
# create instance vars: path (Char), xml (Object, DOM Document), iValidate (Bool), iEnt (Bool), error (Num, Long Int), errorText (Char)
On evClick
Calculate path as
Do FileOps.$getfilename(path,"Select XML file to parse")
# prompts the user for an XML file name and location
If path<>''
Calculate $cinst.$title as path
Calculate xml.$parservalidates as iValidate ## optional
Calculate xml.$replaceentityreferences as iEnt ## optional
Do xml.$loadfile(path,errorText) Returns error
If error=0
OK message Parser Error {[errorText]}
Else
Do method $buildtree ## see below
End If
End If Note that the variables iValidate and iEnt can be added to your window or application (these preferences can be assigned to check boxes on a window) and used to force the XML parser to validate your document and resolve all entities.
Having loaded the XML document into the document object, you can get the root element using the $documentelement() method; the method has no parameters.
The following method prepares the window tree list, gets the root element from the document object and calls another method to build up a complete tree containing all the sub-nodes in the document.
# Method '$buildtree'
# create local variables nodetext (Char), obj (Object), tree (Item ref), treenode (Item ref)
Set reference tree to $cinst.$objs.tree
Do tree.$clearallnodes()
Calculate obj as xml.$documentelement()
# the root element is returned and placed in 'obj'
Do method $getelementtext (obj) Returns nodetext ## see below
Set reference treenode to tree.$add(nodetext)
Do method $addchildren (obj,treenode) ## see belowWhen you have placed an element, such as the root element, into an object variable you can get its text value held in the $tagname property and access its attributes, if the element has any, using the $attributemap() method.
Having created the list of attributes (a named node map) for an element you can step through the list using the $item() method in a For loop to extract each attribute.
The following method gets the text value of the element passed to it and, assuming the element has attributes, adds the attributes in ‘name=value’ pairs. The properties $attname and $attvalue give you the name and value of an attribute.
# Method '$getelementtext'
# create parameter var element (Object)
# create local vars att (Object), attlist (Object), k (Long int), nodetext (Char)
Calculate nodetext as con('<',element.$tagname,'>')
# returns the element or tag name in nodetext
Calculate attlist as element.$attributemap
# builds a 'namednodemap' or list of object attributes: this is empty if there are no attributes and code skips the For loop, otherwise loop adds all attributes of tag
For k from 0 to attlist.$length-1 step 1
# $length is the number of attributes in the named node map
Calculate att as attlist.$item(k)
# $item() returns the specified attribute in the list
Calculate nodetext as con(nodetext,' ',att.$attname,' = ',att.$attvalue)
# $attname and $attvalue are properties of an attribute
End For
Quit method nodetextSince XML documents are highly structured it is relatively easy to step through the node tree and enumerate all its nodes and sub-nodes (children and grandchildren). You can use the $childnodes() method to get a list of children for a node, and then construct each child node according to its type by querying its $nodetype property.
$childnodes(&cErrorText)
returns a node list object listing the children of this object, or NULL and cErrorText if an error occurs
$haschildnodes()
returns true if the object has children; note no parameters
The following method steps through the node tree passed to it and adds the text value of each node to a tree list. Note the switch statement branches on the $nodetype of the current node and constructs the nodetext accordingly.
# Method '$addchildren'
# create parameter vars pObj (Object) and pTree (Item ref)
# create local vars att (Object), attlist (Object), child (Object), j (Long int), k (Long int), nl (Object), nodetext (Char), treenode (Item ref)
Calculate nl as pObj.$childnodes()
For j from 0 to nl.$length-1 step 1
Calculate child as nl.$item(j)
Switch child.$nodetype
Case kXMLNodeComment
Calculate nodetext as con('// ',child.$textdata)
Case kXMLNodeElement
Do method $getelementtext (child) Returns nodetext
Case kXMLNodeProcessingInstruction
Calculate nodetext as con('PI: ',child.$pitarget,
' = ',child.$pidata)
Case kXMLNodeText
Calculate nodetext as con(child.$textdata)
Case kXMLNodeCDATASection
Calculate nodetext as con('CDATA: ',child.$textdata)
Case kXMLNodeAttribute
Calculate nodetext as con(child.$attname, ' = ',child.$attvalue)
Case kXMLNodeEntityReference
Calculate nodetext as 'ER'
Default
Calculate nodetext as con('Unexpected node type: ',child.$nodetype)
End Switch
Set reference treenode to pTree.$add(nodetext)
If child.$haschildnodes()
Do method $addchildren (child,treenode)
End If
End For You can save an XML document to a file on disk using the $savefile() method or to a binary variable using $savebinary().
$savefile(cPath,&cErrorText[,bStripDT=kFalse,iFmt=kXMLformatNone])
saves XML to pathname cPath; returns true for success, or false and cErrorText; strips prolog DOCTYPE if bStripDT is true; kXMLFormat... constant iFmt controls formatting
$savebinary(&xXML,&cErrorText[,bStripDT=kFalse,iFmt=kXMLformatNone])
saves XML to binary variable xXML;r eturns true for success, or false and cErrorText; strips prolog DOCTYPE if bStripDT is true; kXMLFormat... constant iFmt controls formatting
# Method for Save button
# create vars path (Char), errorText (Char), error (Long Int)
On evClick ## Event Parameters - pRow( Itemreference )
Calculate path as
Do FileOps.$putfilename(path,"Specify name of output XML file")
If path<>''
Do xml.$savefile(path,errorText) Returns error
If error=0
OK message Parser Error {[errorText]}
End If
End If The format parameter for the $savefile() and $savebinary() methods is an integer and can take one of a number of constants, as follows:
kXMLFormatNone
The output XML is not formatted; the default if iFmt is omitted (that is, no tabs and carriage-return linefeed sequences are inserted)
kXMLFormatBasic
The output XML is formatted by the insertion of tabs and carriage-return linefeed sequences
kXMLFormatFull
The output XML is formatted by the insertion of tabs and carriage-return linefeed sequences; in addition, text nodes are formatted by removing all leading and trailing spaces, as well as tabs, carriage returns and linefeeds
You can pass the contents of a document object into an Omnis list variable using the $savelist() method. Conversely, you can transfer the contents of an Omnis list, assuming it is in the correct format, to a document object using the $loadlist() method. You can therefore manipulate the contents of an XML document via an Omnis list.
$savelist(&lList,&cErrorText [,bSkipWhiteSpace])
saves the XML specified by the object into the list lList, skipping the whitespace within elements if bSkipWhiteSpace is true; returns true for success, or false and cErrorText for failure.
$loadlist(lList,&cErrorText [,cDocTemplatePath])
loads list lList defining an XML document into the object, returns true for success, or false and cErrorText for failure. cDocTemplatePath is optional and can specify a DTD document template.
The following methods show how you can read an XML document into and out of an Omnis list. The Save List method prompts the user for an XML document, loads the file into the document object, and saves the contents of the object into the Omnis list xmllist.
# method for save list button
On evClick
Calculate path as
Do FileOps.$getfilename(path,"Select XML file to parse")
If path<>''
Calculate xml.$parservalidates as iValidate
Calculate xml.$replaceentityreferences as iEnt
Do xml.$loadfile(path,errorText) Returns error
If error=0
OK message Parser Error {[errorText]}
Else
Do xml.$savelist(xmllist,errorText,iSkip) Returns error
End If
End If The Load List method prompts the user for a file name for the output XML document using the FileOps method $putfilename(), prompts the user to identify a DTD for validation, transfers the contents of the Omnis list to the document object, and saves the contents of the document object to the XML disk file.
# method for load list button
On evClick
Calculate path as ''
Do FileOps.$putfilename(path,"Specify name of output XML file")
If path<>''
Calculate template as
Do FileOps.$getfilename(template,"Select XML document template for output")
Do xml.$loadlist(xmllist,errorText,template) Returns error
If error=0
OK message {Load list failed: [errorText]}
Quit method
End If
Do xml.$savefile(path,errorText) Returns error
If error=0
OK message Parser Error {[errorText]}
End If
End If You can save or transfer a document object containing an XML document to an Omnis list variable and display the document in a tree list object using the $savetree() method. The tree list can be either a standard window tree control or a web component displayed on a remote form.
If true, bExpanded specifies that the tree list is expanded when displayed, bIgnoreDocumentElement specifies that the document root is ignored and not displayed, and bSkipWhiteSpace specifies whether or not white spaces within elements are ignored.
The $savetree() method can be used behind a button or FormFile object to transfer an XML document into a tree list for display. For example, the following remote form allows the user to view an XML document in a web browser.

The following method is behind a Read button (FormFile object) on the remote form. The method prompts the user to locate an XML document and displays the file in a web tree.
# create vars iXml (Object), iList (List)
# iExpanded, iIgnoreDocElem, iSkipWhitespace are linked to the check boxes on the form
# pFileData is passed to the method from the FormFile component and in this case contains the data from the XML document
On evFileRead
Calculate iXml.$parservalidates as kFalse
Do iXml.$loadbinary(,cErrorText,cSearchDir) Returns #1
If #1=0
Do $cinst.$showmessage(cErrorText)
Else
Do iXml.$savetree(iList, cErrorText, iExpanded, iIgnoreDocElem, iSkipWhitespace) Returns #1
If #1=0
Do $cinst.$showmessage(cErrorText)
End If
Do $cinst.$redraw()
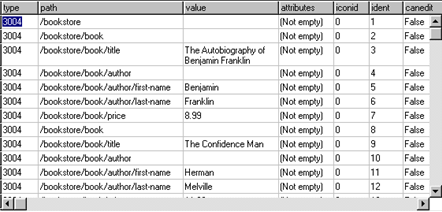
End If The first parameter of the $savetree() method is an Omnis list variable. When the method is executed the list is populated with the XML data from the document object. The list has a number of columns that are required to draw the tree list. The columns are: nodeType, path, value, attributes, iconid, ident, canedit, flags, and textcolor which are required to draw the tree list.
If you wish to build a document containing an XML construct such as a DTD or something that cannot be built using oXML, then provided that this information is fixed for each XML document, you can handle this by using a document template. The approach to building a document becomes:
1. Load the document template; this may contain an inline DTD or link to external DTD file, for example.
2. Add information to the document (elements, text etc.).
3. Save the document.
XML documents can contain characters from any language including those represented by Unicode. oXML only works with documents that contain characters that can be converted to the local code page of the environment in which Studio is running, for example, under Windows the ANSI character set is used. Documents containing other characters can be loaded, but will not have the correct data when used in Omnis Studio.
You can use the static function $removeinvalidcharacters to remove invalid characters from XML data.
Invalid XML characters are deemed to be characters less than space, that are not tab, carriage return or linefeed.
The oXML external component makes the handling of XML documents simple within an Omnis application. It treats each node as a separate object, enabling easy searching and manipulation of these nodes within the document. To create an XML document you need to create an Omnis Object with the subtype DOM document object and add different elements to the object. You can do this using the methods built into the document object.
To create an XML document, first you must create a DOM document object (in the method editor Variable pane, Type is Object, and Subtype is under external objects -> DOM document, as described earlier in this manual). This is the master object of your document, and allows you to create, search, edit and delete all types of nodes within your document.
Your XML document will be made up of several ‘elements’. Each element must have a name, but may also have several other properties associated with it, such as attributes, text, and comments. These will be discussed later.
Each element may also contain other elements (known as its children), thereby creating the tree type structure associated with the XML document.
Elements (and all other objects) are created by the DOM document object using its $createXXX() methods. For example, the following method returns an element object, oRoot, named ‘Root’:
# Define oXML as Object, with subtype DOM document object
# Define lError as Character
# Define oRoot as Object, with subtype DOM Element object
# Define oObj as Object, no subtype
Do oXML.$createelement('Root',lError) returns oRootOnce you have created an element object, you must insert it into the document. This must be done from the element object that will become the parent of the element you are about to add. The element object has two methods for this:
$appendchild()
inserts the element at the end of its list of children.
$insertbefore()
inserts the element before the stated object.
As there are no elements when you create your first element, you must use the DOM document object as its parent: this creates what is known as the ‘Root’ element, of which there can only be one, and all other elements are descendants of this.
Do oXML.$appendchild(oRoot ,lError)
Do oXML.$createelement('Element1' ,lError) returns oObj
Do oRoot.$appendchild(oObj, lError)The above method inserts the Root element into the document, then creates another element (Element1), which it returns in oObj (since oObj has no subtype, its type is defined when it has an object assigned to it; this keeps the number of variables down). The element is then inserted as a child of oRoot.
Although you have now added some elements, they contain no information. An element may have various properties associated with it. These are all added as children of the element, in the same way that elements are added as children of their parent elements. These may be added before or after inserting the element.
There are two possible ways of displaying text, parsed and unparsed. The usual method is parsed, which means your XML parser will evaluate the text. For example, “Apples & Pears” will be equated to “Apples & Pears”. Using unparsed will not evaluate the text and so will express it literally, in this case, “Apples & Pears”.
# to create PARSED text
Do oXML.$createtextnode("Apples & Pears", lError) Returns oObj
# to create UNPARSED text
Do oXML.$createcdatasection("Apples & Pears", lError) Returns oObjWill create a text node containing the text, then to add it to the element oElement:
Do oElement.$appendchild(oObj, lError)Attributes are added in a very simple manner. They require just a name and a value, and are added to the element with its $setattribute() method, as follows:
Do oElement.$setattribute("Colour","red",lError) This will add the attribute Colour = “red” to the element oElement. You can use this method many times to add multiple attributes to the same element. Attributes can also be added using the usual method, such as oXML.$createattribute(), then the attribute is added as a child of element.
Comments are not processed by XML parsers, but are present only to improve readability of the XML document. They follow the general form:
Do oXML.$createcomment("Your comment here", lError) Returns oObj
Do oElement.$appendchild(oObj, lError) Processing instructions are used in XML as a way to keep processor-specific information in the text of the document. They store a ‘target’ and a value to pass that target. Again, these are created in the same way as the other objects, that is, oXML.$createprocessinginstruction(), then the processing instruction is added as a child of an element.
Entities are declared in the DOM document’s DocumentType object. The oXML component is based on DOM level 2, which does not support the editing or creation of DocumentType objects. Therefore, the oXML component only allows the reading of entities already defined in an existing XML document.
Once you have created your DOM document in Omnis, with all the elements and so on in place, you need to save the document object to an .xml file. To do this, you can use the $savefile() method in the DOM document object.
Do oXML.$savefile("C:\MyFolder\MyXML.xml", lError, kFalse, XMLFormatFull)The last argument of the $savefile() method allows you to specify the formatting of the output XML file. The formatting options let you specify whether or not to add carriage returns and line feeds, and to remove spaces, etc. Different parsers may require different formatting settings to display your XML file.